Parasoftのテストデータ管理への新しいアプローチは、AI、機械学習、データシミュレーションを利用して物理的なエンドポイントとデータベースを置き換え、並列統合テストによって機能テストをシフトレフトします。どのような仕組みなのでしょうか?以下をご覧ください。
テストデータの問題
ソフトウェアの妥当性確認と検証は、エンタープライズソフトウェア開発において最も時間と費用がかかる工程の1つです。テストは難しいという認識が一般的に受け入れられている一方で、しばしば根本的な原因が見落とされています。テストデータの取得、保存、保守、および使用は、膨大な時間がかかる手強いタスクだということです。
業界のデータを見ると、アプリケーション開発およびテスト時間のうち、最大で60%をデータ関連タスクが占め、その大部分がテストデータ管理であることがわかります。スケジュールの遅延や予算の浪費につながることも問題ですが、それらは問題の一部にすぎません。テストデータが不足していればテストが不十分になります。これははるかに大きな問題であり、必然的に欠陥が運用コードに忍び込んでしまいます。
TDM市場の従来のソリューションでは、テストデータの課題を十分に解決できませんでした。そのような課題のいくつかを見てみましょう。
テストデータ管理に対する3つの従来型アプローチ
従来のアプローチでは、本番データベースのコピーを作成するか、あるいはその反対に、合成データを生成して使用します。従来型アプローチとして次の3つがあります。
1. 本番データベースを複製する
テスターは、本番データベースを複製してテストデータを作成することができます。本番データベースのコピーであるため、必要なインフラストラクチャも複製する必要があります。セキュリティとプライバシーのコンプライアンスの観点から考えると、機密にすべき個人情報を厳重に保護する必要があるため、多くの場合、マスキングを使用してデータを難読化します。
2.本番データベースのサブセットを複製する
本番データベースのサブセットは、本番データベースの部分的なクローンであり、テストに必要な部分のみが含まれます。このアプローチでは、ハードウェア要件は緩和されますが、上の方法と同様に、データのマスキングおよび本番データベースと同様のインフラストラクチャが必要です。
3.データを生成/合成する
合成したデータは、顧客データに依存しないながらも、テストに十分に実用的に利用できるものです。レガシーな本番データベースの複雑さを合成によって再現することは大変なタスクですが、データベースを複製するアプローチにある、セキュリティとプライバシーの課題を避けることができます。
従来のTDMアプローチの問題点
最初に、エンタープライズTDMに対する最も単純な(そして驚くほど一般的な)アプローチを検討してみましょう。それは、本番データベースのクローンを(サブセット化させて、またはさせずに)作成することです。なぜこのアプローチがそれほど問題なのでしょうか?
- インフラストラクチャの複雑さとコスト。おそらく、従来のTDMアプローチの最大の弱点は、レガシーデータベースがメインフレームに存在したり、複数の物理データベースで構成されたりする場合があるという点でしょう。1 つのチームのために1つの本番システムだけを複製していては、費用がかさんでしまいます。
- データのプライバシーとセキュリティ。本番データベースを使用する場合、プライバシーとセキュリティは常に懸念すべき事項であり、テスト環境がプライバシーおよびセキュリティ管理の基準を満たしていないことがよくあります。マスキングはこれらの懸念に対処するための一般的なソリューションであり、個人を特定できる情報が表向きにならないように機密情報を作り変えます。しかし、テストデータは匿名化を解除することが可能であるため、素晴らしいテストチームがいかに努力をしようとも、個人情報が漏洩するリスクをゼロにすることはほぼ不可能です。たとえば、GDPR(EU一般データ保護規則)に準拠する必要がある企業は、複製したテスト環境がプライバシーコントロールの要件を満たしていることを規制当局に証明するのに苦労するかもしれません。
- 並列性の欠如とデータの競合。インフラストラクチャのコストを考えると、使用できるテストデータベースのセットはおのずと限られるため、複数のテストを並行して実行すると、データの競合が懸念されます。たとえば、あるテストを実行する際に、他のテストが依存しているレコードを削除または変更する場合があります。このとき並列性が欠如することで、テストの効率が低下してしまいます。テスターはテストセッションが終了するたびにデータの整合性について確認を取らなければなりません。
- サブセット化は有効ではない。インフラストラクチャをそれほど必要としない、管理が容易なサブセットを作成することは可能であるかもしれませんが、それは複雑なプロセスを含みます。参照整合性を維持する必要があり、プライバシーとセキュリティの問題はサブセットの中にも依然として存在するからです。
- データの合成はプライバシーの問題を解決するが、データベースとドメインに関する多くの専門知識が必要。現実的なテストデータベースを作成してデータを入れ込むには、既存のデータベースに関する詳細な知識と、テストに適したデータを使用して合成版のデータベースを再現する能力が必要です。そのため、このアプローチはセキュリティとプライバシーの問題の多くを解決しますが、データベースを作成するには非常に多くの時間がかかります。テストデータベースが大きい場合は、依然としてインフラストラクチャの問題が関係し、同時に使用できるテストデータベースの数によっては並列処理が制限される可能性があります。
データシミュレーションでテストデータ管理(TDM)を簡単に
ParasoftのSOAtest および Virtualizeに導入されたシンプルで安全なテストデータ管理アプローチは、これらの従来の問題を解決できます。今までのアプローチとはどう違うのでしょうか?
大きな違いは、テストや通常のアプリケーションの実行時に、API呼び出しとJDBC / SQLトランザクションからトラフィックをキャプチャすることでテストデータを収集するという点です。必要に応じてキャプチャされたデータにマスキングを行ったうえで、データモデルを生成し、Parasoftのテストデータ管理インターフェイスに表示します。インターフェイス内でモデルのメタデータおよびデータ制約の推測と構成を行い、追加のマスキング、生成、およびサブセット操作を実行できます。以下の画面キャプチャに示すように、これは、使い捨て可能なデータセットをいくつも簡単にセットアップできるセルフサービスポータルであり、柔軟性と扱いやすさに優れたテストデータを提供します。
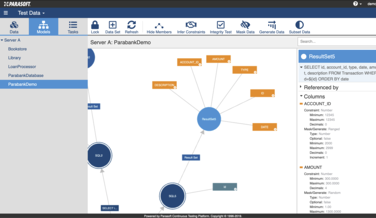
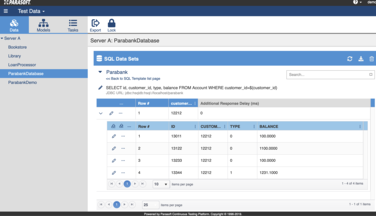
Parasoftのテストデータ管理テクノロジーは、サービス仮想化と組み合わせることでより力を発揮します。制限があるバックエンドの依存関係をシミュレートし、テストアクティビティの障害を取り除きます。たとえば、共有の物理データベースから仮想化されたデータベースに依存先を置き換えて、JDBC / SQLトランザクションをシミュレートする場合などがよい例でしょう。こうすることで、競合を回避し、独立したテストを並列で実行できるようにします。Parasoftのテストデータ管理エンジンによって、テスターはニーズに合わせて個別にカスタマイズされたテストデータを生成、サブセット化、マスク、および作成できるようになり、サービス仮想化能力が向上します。
サービス仮想化は、データベースなどの共有される依存先サービスを置き換えることにより、データベース環境をホストするインフラストラクチャを不要にし、複雑さを軽減します。これは、テストスイートが分離されること、また、極端なケースや特殊なケースをカバーできることを意味します。仮想化された依存先サービスは「本物」ではありませんが、データベースへの挿入操作や更新操作などのステートフルアクションも、仮想資産内でモデル化できます。以下の概念図を参照してください。
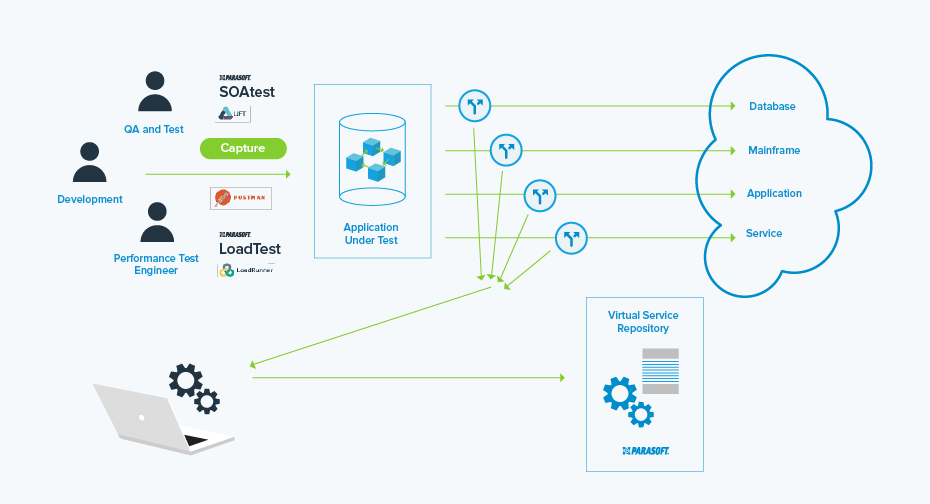
このアプローチの主な利点は、データベースのクローンを作成する場合の複雑さやインフラストラクチャのコストを考える必要がなく、他のテストデータメソッドを採用した場合よりもはるかに早い段階でAPIレベルのテスト(統合テストなど)を行えることです。
このアプローチには、他にもいくつかの利点があります。
- 基盤となるデータベースインフラストラクチャを必要としないため、開発者やテスターのワークステーションでローカルに実行できます。
- 各テスターに固有の隔離されたテスト環境があるため、共有のテストデータベースを使用する場合とは違って、データの競合が発生せず、データの整合性に関する懸念もありません。テストは高度に並列化され、従来のアプローチで発生していた待ち時間や無駄なサイクルがなくなります。
- テスターは、破損やその他の問題を引き起こす可能性のある特殊なケースも、テストデータベースを使用して簡単にカバーできます。各テスト環境は分離されているため、テスターは共有リソースの整合性を気にすることなく、破壊的テスト、パフォーマンステスト、およびセキュリティテストを簡単に実行できます。
- 複数のチームでテストとデータを共有して再利用するのが簡単なほか、APIテストをセキュリティテストやパフォーマンステストなど他の目的用にカスタマイズすることもできます。
- 仮想サーバーを使用することで、基盤のデータベーススキーマの複雑さを取り除くことができます。ステートフルテストによって現実的なシナリオを実行できます。
- 動的マスキングで必要なデータのみをキャプチャすることにより、クローンデータベースが不要になるため、共有クローンデータベースのメンテナンスではなく、APIの統合テストに集中できます。
物理データベースでのテストも引き続き必要ですが、ソフトウェアデリバリープロセスの終盤、つまりシステム全体が利用可能になったときにだけ行うだけで済みます。このテストデータ管理アプローチは、実際のデータベースを使用したテストの必要性を完全になくすものではありませんが、ソフトウェア開発プロセスの初期段階でのデータベースへの依存を軽減して機能テストの実行を促進させます。
まとめ
エンタープライズソフトウェアのテストデータ管理に関する従来のアプローチは、本番データベースとそのインフラストラクチャのクローンを作成することに依存しており、コスト、プライバシー、およびセキュリティに関する懸念が多くあります。これらのアプローチは適用性に乏しく、結果としてテストリソースの無駄が発生します。Parasoftの新しいソリューションは、テストとオンデマンドでのテストデータの再構成に焦点を当て、統合テストを並列で行うことを可能にし、テストの重要なステージをシフトレフトします。
(この記事は、開発元Parasoft社 Blog 「Making Test Data Management (TDM) Easier with Data Simulation」2019年8月8日の翻訳記事です。)
Parasoft SOAtest/Virtualizeについて
![]()
>